All that has been said so far is still preliminary to the main event, for the data structures implemented so far, though dynamic, have not been of the kind whose number of entities could grow and shrink with the needs of the program at run time. In each instance to date in this chapter, there were static variables related to each dynamic instance. It is useful, but does not reach the goals set for this chapter, to declare large numbers of pointer variables (or opaque ones). In order to have truly dynamic collections, there must be a way to free the program from any presuppositions about the number of dynamic entities. Declaring a 500-item static array of pointers does not respond adequately to this challenge.
The perceptive student will respond that the solution is to make new pointer variables as the program goes along (dynamically). In order for this to happen, the pointer type must itself be a field in the record holding the data. Then, every time memory is allocated for a new data record, so is a new pointer variable. Consider the declarations:
TYPE
ItemPointType = POINTER TO ItemData;
ItemData =
RECORD
data : INTEGER;
(* more data fields here *)
toPoint : ItemPointType; (* Pointer field *)
END;
VAR
itemPoint : ItemPointType;
A call to obtain dynamic memory via
NEW (itemPoint);
will obtain enough memory not only for the requisite data, but also for another pointer, via the additional field at the end of the data record. The next time a dynamic item is needed, a program variable is not necessary, for one can call
NEW (itemPoint^.toPoint);
and the time after that
NEW (itemPoint^.toPoint^.toPoint);
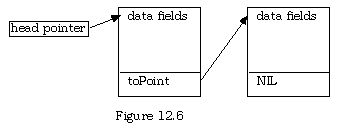
and so on, indefinitely. The static program variable itemPoint points to the first of the dynamic records, and then each in turn points to the next one, and so on. Everything beyond the initial pointer is dynamic. Such a chain of records is called a linked list, and with a little work, does have the potential to be used to hold the data in the airline reservation problem mentioned in section 12.4.3.
A linked list consists of a sequence of dynamically allocated data items, each element of which includes a pointer to the next item on the list. The first item on the list is called the head; the last item is called the tail, and the program pointer that points to the head item is called the head pointer.
Notice that the last item on the list cannot point anywhere. The value of its pointer variable should be set to NIL as a terminal flag.
Also, look carefully at the declarations above. Do you notice anything unusual? Those readers who are operating with a one-pass compiler, and those who believe in declare-it-before-you-use-it (which should be everyone else), might object that this declaration makes use of an entity of type ItemData (to declare the type ItemPointType) before declaring it. Of course, if one writes it the other way around one has to use ItemPointType before declaring it. This appears to violate a rule that this text has been very careful about following up to now.
Indeed, even in multi-pass compilers, there is still a declare-it-before-you-use-it-in-a-declaration rule, and the ISO standard actually distinguishes between what are here called single-pass and multiple-pass compilers by referring to them as following either a declare-before-use rule or a declare-before-use-in-declarations rule, respectively. Clearly the former is a greater restriction than and includes the latter.
ISO Modula-2 expresses the rule that allows such circular references in this case in this manner:
The use of an identifier within a new pointer type follows the keywords POINTER TO and is shielded from the declare-before-use-in-declarations that normally applies.
This requires the declaration of the pointer to be the first of the two. Although this rule does not strictly say how far away in the program text the declaration of the type pointed to must be located, it should be placed immediately adjacent to the declaration of the pointer type as in the example above, for the sake of clarity. Indeed, some implementations may have an additional rule requiring either this proximity, or at least that the second declaration be under the same TYPE heading as the first.
Besides the beginning step of initialization, the maintenance of a linked list needs to take into consideration:
It is probably best to begin by considering the task of appending, that is of adding at the end of a list. Quite apart from the fact that most lists have things added in that position from time to time, one needs to add the first item to the end of the list before one will even have a list. Assume that, in a similar fashion to the last section, the following declarations have been made:
TYPE
ItemPointType = POINTER TO ItemData;
ItemData =
RECORD
number : CARDINAL;
(* more data fields here *)
toPoint : ItemPointType; (* Pointer field *)
END;
VAR
head, point : ItemPointType;
item : ItemData;
At this stage, there is no list, just an uninitialized pointer and data item of the correct type to be a list element. The execution of NEW (head) creates an instance of the ItemData type that can be the first item in the list.
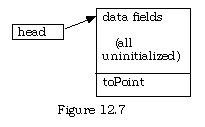
Next assign a copy of item (perhaps filled in by keyboard inputs) to point^. All the data fields are filled in, and so is the pointer field, but with no particular initialized value. Give it the value NIL to begin with.
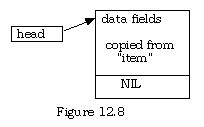
Here is the code:
PROCEDURE AppendFirst (item : ItemData); (* Pre:the data fields of the item have been filled in Post : head now points to the first record, which points nowhere *) BEGIN NEW (head); head^ := item; (* "point^" is the actual dynamic record *) head^.toPoint := NIL; (* this item points nowhere yet *) END AppendFirst;
Now if one assumes that at some point the list has one or more items in it with the toPoint filed of the last one containing the value NIL, the strategy for appending an item is to search through the list until the last one is found (previousItem.topoint = NIL), then create space for and assign the new item, change the last toPoint previously present to point to the new item, and change the toPoint of the new one to NIL. Here is the code:
PROCEDURE Append (item : ItemData);
(* Pre:the data fields of the item have been filled in
Post : old last one now points to the item record, which points nowhere *)
VAR
point, temp : ItemPointType ;
BEGIN
temp := head;
WHILE temp^.toPoint # NIL
DO (* search through the list *)
temp := temp^.toPoint (* for the last item *)
END;
NEW (point);
point^ := item;
temp^.toPoint := point; (* set old last one to point to new one *) point^.toPoint := NIL; (* defines new end *)
END Append;
Actually, if one were doing a lot of adding to the end of the list, it would make more sense to keep another program variable that pointed to the last item, that is, that kept the address of the last section of memory assigned by the NEW command. This kind of variable is usually called a tailpointer.
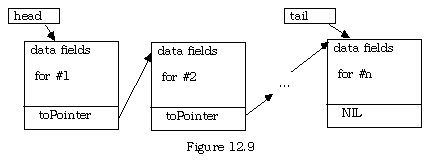
Now the addition of a member to the list (even the first one, where the head and tail pointers would have both been initialized to NIL) could go like this:
(* in the main program *)
head2 := NIL;
tail2 := NIL;
PROCEDURE Append (item : ItemData); (* pass in item to add *)
VAR
temp : ItemPointType ;
BEGIN
NEW (temp); (* get space *)
temp^ := item; (* assign it *)
temp^.toPoint := NIL;
IF head2 = NIL
THEN
head2 := temp (* Do this only if first one *)
ELSE
tail2^.toPoint := temp (* otherwise make old tail item *)
END; (* point to new tail *)
tail2 := temp (* reset tail pointer always *)
END Append;
One advantage of working with dynamic data is that once an item is dynamically established via NEW and the assignment of data, it need not be moved around in memory. This contrasts with an earlier situation where if one had, say, 100 Records in an array and wished to insert a new one at position [3], then everything from position [3] to the last active one would have to be moved to the next higher index number to make room. This may involve a very large amount of memory reassignment.
FOR count := last TO 3 BY -1 (* up to 97 steps to make one place *)
DO
list [count + 1] := list [count]
END; list [3] := item;
For very large arrays, and records that have several fields, the amount of time consumed in such a loop is unacceptable. One solution to this problem was given earlier in the chapter, and involved employing an array of pointers to save space and assignment time. Another solution involves implementing the collection as a linked list. Here too, the insertion of a new item just before a position k is much easier.
insert =
set traverse pointer point to head
move along list k-1 steps (point points to item k-1)
get new dynamic memory for item with pointer temp
assign the passed item to temp^
link the new item in
copy toPoint from item k-1 to temp^.toPoint
copy temp to the toPoint from item k-1
Here is a diagram showing the old link that is discarded and the new links that are filled in:
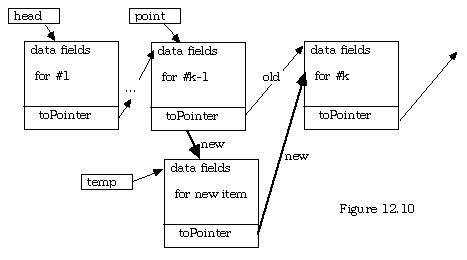
Note that the code given below also handles the special cases of inserting before item 0 or 1 (both taken as inserting at the head) and "before" an index that is beyond the tail (interpreted as appending.)
PROCEDURE InsertBeforeIndex (item: ItemData; index: CARDINAL);
(* pass in item to insert and place to put it
Post: if index is 0 or 1 insert at head;
else, insert before given index or at end if given index too high *)
VAR
point, temp : ItemPointType;
count: CARDINAL;
BEGIN
point := head;
count := 2;
WHILE (count < index) AND (point^.toPoint # NIL)
DO
point := point^.toPoint;
INC (count);
END; (* point now points to item # index-1 *)
NEW (temp); (* get space for item *)
temp^ := item; (* assign it *)
IF point = head (* i.e. 2 >= index, loop didn't execute *)
THEN (* goes before item [1] *)
temp^.toPoint := head;
head := temp;
ELSIF count < index THEN (* index past tail *)
point^.toPoint := temp; (* so do an append *)
temp^.toPoint := NIL;
ELSE (* typical insert in between *)
temp^.toPoint := point^.toPoint; (* new item points to index *)
point^.toPoint := temp; (* item# index - 1 points to new one *)
END; (* if *)
END InsertBeforeIndex;
Rather than move a large amount of data around in memory as would have to be done with array insertion, one just makes item# (index - 1) point to the new item, and the new item point to the old item# index. Changing two pointer values suffices to link in the new item.
With this code done, it should be easy to see how an item can be removed from the list by breaking a link, establishing a new one, and disposing of the memory associated with the item removed.
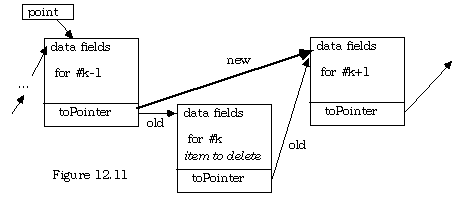
PROCEDURE Delete (index : CARDINAL);
VAR
point, temp: ItemPointType;
(* temp will hold one to dispose of *)
count: CARDINAL;
BEGIN
IF head = NIL (* nothing in list *)
THEN
RETURN
END;
point := head;
count := 2;
WHILE (count < index) AND (point^.toPoint # NIL)
DO
point := point^.toPoint;
INC (count);
END; (* p now points to item # index-1 *)
IF point = head
THEN
temp := head; (* get one to dispose *)
head := point^.toPoint (* repoint head *)
ELSIF count < index THEN (* index past tail *)
RETURN (* cannot delete what isnt there *)
ELSE
temp := point^.toPoint; (* pointer to the one that goes *)
point^.toPoint := temp^.toPoint (* re-link to next one *)
END; (* if *)
DISPOSE (temp); (* reclaim its memory *)
END Delete;
With these simple procedures, it is now possible to maintain a linked list and to have it contain as many items as the memory will allow.
Of course, there are also disadvantages to using linked lists. Although it may be a simple matter to put items into a list in a particular order (do comparisons first before inserting, or include code to maintain the list sorted as each item is inserted) it would be very tedious indeed to rearrange the list after it was in place. Just swapping two list items would not be a trivial exercise, and moving items around in the manner needed for a sort is not to be thought of. Arrays are much better for the kind of data access that requires frequent reference to items in the same amount of time by their index number in the structure (random access). Note, on the other hand that:
A linked list is by its very nature a sequentially accessed structure.
Nor is it possible to get around the sequential nature of the access by calculating an address based on the starting point and the size and index of an item as was done earlier in this chapter for a dynamic array. The latter was assigned its memory in a single block, and the computation of an address in order within this block made sense. The linked list is not assigned memory in a continuous block at all. Indeed, the assumption is that the locations of successive items in the list could be anywhere in memory, and that the only glue that holds the whole structure together is the pointers that chain one to the next.
The student is invited to build a test harness for the routines above, or, better yet, to incorporate them (with some minor changes) into a library module encapsulating a list ADT for a favourite data item and then test this with an application module. Such a library module would have to contain an implementation of a list type, perhaps
TYPE
ItemPoint = POINTER TO Item;
Item =
RECORD
(* all the data fields *)
toPoint : ItemPoint
END;
List = POINTER TO ListData; (* opaque redefinition *)
ListData =
RECORD
head, tail : ItemPoint;
END;
Procedures would have to be included to create one of these lists (set up a data record for it,) dispose of one (delete all items and dispose of the list data record,) and to fetch and update data at some node.
REMINDER: Do not forget to import both ALLOCATE and DEALLOCATE from the module Storage before making use of NEW and DISPOSE.